Clean Code com NestJs e Typescript
“Your architectures should tell readers about the system, not about the frameworks you used in your system” — Robert C. Martin

Artigo original: https://medium.com/better-programming/clean-node-js-architecture-with-nestjs-and-typescript-34b9398d790f
Depois de trabalhar com NestJs e TypeScript achei uma boa ideia escrever um novo artigo sobre o assunto. Desta vez, vamos pegar o super poder do Typescript e as metodologias e ferramentas dos NestJs e aproveitá-los para nossos benefícios.
Neste artigo, vou explicar sobre Clean Code do zero.
Então, o que é arquitetura limpa?
Suas arquiteturas devem informar aos leitores sobre o sistema, não sobre os frameworks que você usou em seu sistema — Robert C.Martin
Essa arquitetura tenta integrar algumas das principais arquiteturas modernas, como hexagonal architecture, onion architecture, e screaming architecture em uma arquitetura principal.
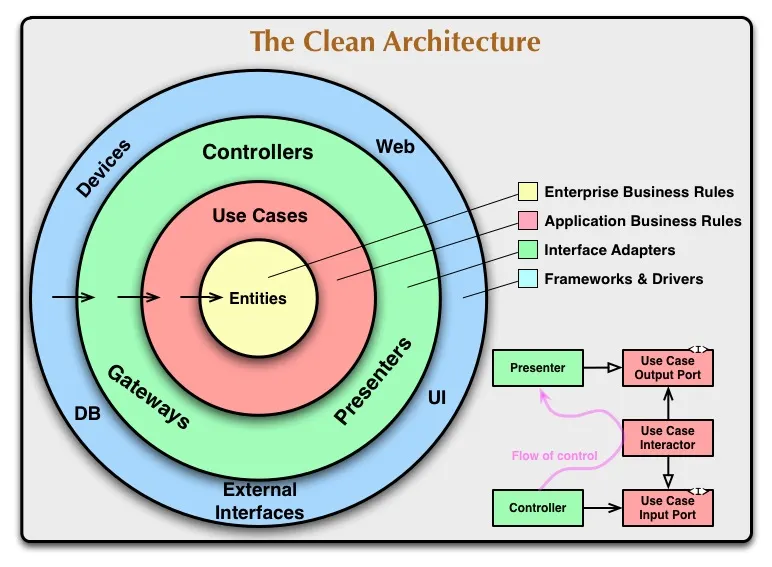
Este diagrama foi retirado do artigo oficial de Robert C. Martin. Eu recomendo ler seu artigo antes de mergulhar na implementação. Este é o melhor conhecimento de origem sobre esta arquitetura.
Algumas palavras sobre este diagrama e como lê-lo (não se preocupe se você ainda não o entendeu, vamos nos aprofundar em cada camada neste artigo):
- Camadas: Cada anel representa uma camada isolada na aplicação.
- Dependência: A direção da dependência é de fora para dentro. Isso significa que a camada de entidades é independente e a camada de frameworks (web, UI, etc.) depende de todas as outras camadas.
- Entidades: Contém todas as entidades de negócios que constroem nossa aplicação.
- Casos de uso: é aqui que centralizamos nossa lógica. Cada caso de uso orquestra toda a lógica para um caso de uso de negócios específico (por exemplo, adicionar novos clientes ao sistema).
- Controllers e presenter: Nossos controllers, presenters e gateways são camadas intermediárias. Você pode pensar neles como um portão de entrada e saída para os casos de uso.
- Frameworks: Esta camada possui todas as implementações específicas. O banco de dados, os frameworks da web, os frameworks de tratamento de erros, etc. Robert C. Martin descreve essa camada: “Essa camada é para onde vão todos os detalhes. A web é um detalhe. O banco de dados é um detalhe. Nós mantemos essas coisas do lado de fora, onde elas podem causar pouco dano.”
Neste ponto, você provavelmente está dizendo para si mesmo: “Banco de dados está na camada externa, um banco de dados é um detalhe?” O banco de dados deve ser minha camada principal.
Eu amo essa arquitetura porque ela tem uma motivação inteligente por trás dela:
Em vez de se concentrar em estruturas e ferramentas, essa arquitetura se concentra na lógica de negócios do aplicativo. É independente do framework (tanto quanto pode ser).
Isso significa que não importa qual banco de dados, estrutura de desenvolvimento, interface do usuário ou serviços externos você está usando, as entidades e a lógica de negócios do aplicativo sempre permanecerão as mesmas.
Podemos mudar todos os itens acima sem mudar nossa lógica. É isso que torna tão fácil testar aplicativos criados com essa arquitetura. Não se preocupe se você ainda não entendeu isso, vamos explorá-lo passo a passo.
Neste artigo, descompactaremos lentamente as diferentes camadas da arquitetura por meio do exemplo de um aplicativo.
Como qualquer outra arquitetura, existem muitas abordagens diferentes para implementá-la, e cada abordagem tem sua própria consideração e compensações.
Neste artigo, darei minha interpretação de como implementar essa arquitetura com NestJs. Tentarei explicar as diferentes considerações de implementação ao longo do caminho.
Vamos dar uma olhada mais de perto no aplicativo de exemplo.
Exemplo de aplicativo
Nosso aplicativo de exemplo representará um microsserviço simples que oferece suporte a operações CRUD em um repositório de livros.
Neste artigo, implementaremos a API de serviço camada por camada. Você pode encontrar todo o código no repositório do GitHub. Este artigo contém frações do código, mas a melhor abordagem (na minha opinião) é explorar o código enquanto lê este artigo.
Em nossa implementação vamos usar NestJS.
Nest é uma ferramenta para criar aplicativos Node.js no lado do servidor eficientes e escalonáveis. Ele usa JavaScript moderno, é construído com TypeScript (preserva a compatibilidade com JavaScript puro) e combina elementos de OOP (Programação Orientada a Objetos), FP (Programação Funcional) e FRP (Programação Reativa Funcional). — Repositório npm oficial do Nest
Basicamente, o Node.js permite que você crie aplicativos do lado do servidor da maneira que você quiser, isso é bom em alguns cenários, mas também pode ser um problema onde cada equipe constrói seus aplicativos de uma maneira diferente, cada um com suas próprias opiniões. você não tem unidade em seus projetos e pode ficar confuso muito rapidamente se você não souber o que está fazendo. NestJs é um framework Node.js opinativo, está fornecendo ferramentas como:
- Injeção de dependência
- Separação de código com módulos
- Controllers
- Middleware
- Filtros
- Guardas
Embora este não seja um artigo do NestJs, tentarei explicar alguns dos princípios básicos durante este artigo.
Camada de Entidades e Casos de Uso
O código nesta camada contém regras de negócios específicas do aplicativo. Ele encapsula e implementa todos os casos de uso do sistema. Esses casos de uso orquestram o fluxo de dados para as entidades e direcionam essas entidades a usar suas regras de negócios em toda a empresa para atingir as metas do caso de uso. — Robert C. Martin
No coração da aplicação, temos duas camadas:
- Camada de Entidades: Contém todas as entidades de negócios que constroem nossa aplicação.
- Camada de casos de uso: contém todos os cenários de negócios que nosso aplicativo oferece suporte.

Percorreremos a arquitetura de dentro para fora, ou na direção oposta da regra de dependência.
No interior, temos camadas de núcleo independentes. Essas camadas contêm entidades de negócios e lógica de negócios. Frameworks são criaturas raras nessas áreas, essas camadas devem mudar, principalmente devido a mudanças no negócio.
À medida que avançamos para as camadas externas, encontraremos mais frameworks e mais códigos que mudam ao longo do tempo por motivos de tecnologia ou eficiência.
As entidades são uma camada independente e os casos de uso dependem apenas delas.
Entidades
As entidades de negócios em nosso aplicativo são:
Author
- Id
- First Name
- Last Name
Genre
- Name
Book
- Id
- Title
- Author
- Genre
- Publish Date
Essa camada é independente, o que significa que você importará módulos de diferentes camadas.
Esta camada não seria afetada por mudanças externas como serviços, roteamento ou controllers.
Você pode encontrar todo o código de entidades em nosso aplicativo de exemplo na pasta src/core/entities.
Casos de uso
É aqui que centralizamos nossa lógica. Cada caso de uso orquestra toda a lógica para um caso de uso de negócios específico. Nossa API de aplicativo precisa oferecer suporte a esses casos de uso (eu escolhi uma amostra deles):
- Obter uma lista de todos os livros.
- Obtenha detalhes de um único livro.
- Adicionar novo livro.
- Adicionar novo autor.
Adicionar caso de uso de livro
Vamos examinar e mergulhar no caso de uso “Adicionar novo livro”. As principais responsabilidades do caso de uso são:
- Validação de regras de negócios.
- Verifique se o livro não existe no DB.
- Crie um novo objeto de livro.
- Persista nosso novo livro em DB.
- Atualize o sistema CRM da biblioteca.
Observando as responsabilidades do caso de uso, podemos ver que o caso de uso tem duas dependências:
- Serviços de banco de dados: O caso de uso precisa persistir os detalhes do livro e verificar se ele não existe no sistema. Essa funcionalidade pode ser implementada como uma classe que chama SQL ou MongoDB, por exemplo.
- Serviços de CRM: O caso de uso precisa notificar o aplicativo de CRM da biblioteca sobre o novo livro. Esta funcionalidade pode ser implementada como um serviço que chama um sistema externo (pode ser qualquer sistema).
Uma opção é exigir implementações do banco de dados e dos serviços de CRM no próprio caso de uso (chamar diretamente ao SQL SDK, por exemplo). Essa opção fará com que as implementações do nosso banco de dados e serviço de CRM sejam fortemente acopladas aos nossos casos de uso.
Qualquer alteração nos serviços de banco de dados/CRM (como alterações do SDK) levará a alterações em nosso caso de uso. Essa opção quebrará nossas suposições de arquitetura limpa que os casos de uso expressam o processo de negócios e que as estruturas (como banco de dados e serviços externos) são invisíveis para eles.
Nossos casos de uso só conhecem as entidades e a lógica de negócios. Além disso, testar a lógica dos casos de uso se tornará mais difícil.
OK, vamos supor que o caso de uso não saiba nada sobre bancos de dados como SQL ou MongoDB. Ele ainda precisa interagir com eles para realizar as tarefas (como persistir um livro no banco de dados), mas como diabos ele pode fazer isso se não os conhece?
A solução é construir um gateway entre o caso de uso e o mundo externo.
É aqui que a abstração e a injeção de dependência vêm em nosso socorro. Em vez de criar dependências em um banco de dados específico ou sistema financeiro específico, estamos criando dependências em abstração. Mas, afinal, o que são abstrações?
Abstração é a maneira de criar blueprints de um serviço sem implementá-lo. definimos apenas a funcionalidade que precisamos do serviço.

Com abstrações, definiremos um contrato entre os casos de uso e os frameworks. Basicamente, os contratos são as assinaturas de função dos serviços desejados. Por exemplo, o serviço CRM precisa fornecer uma função “notify” que obtém um objeto Book como parâmetro e retorna uma promessa com um valor booleano.
Dependências de casos de uso
Vamos definir nossas abstrações, precisamos:
- Abstração de serviços de dados
- Abstração de serviço de CRM
Nossa abstração de serviço de dados precisa expor 3 repositórios:
- Repositório de livros
- Repositório do autor
- Repositório de gêneros
Cada um desses repositórios precisa nos fornecer funcionalidades CRUD como: find, findById, Insert, Update, Delete, etc…

Principais abstrações
Você pode encontrar todas as abstrações em nosso aplicativo de exemplo em src/core/abstracts.
Primeiro vamos dar uma olhada em nossa abstração de serviços de dados:
- Repositório genérico : Cada repositório de entidade precisa dar suporte a operações básicas de crud. Eu criei um repositório genérico que servirá como classe abstrata para todos os repositórios de entidades, se precisarmos de funcionalidades diferentes para cada repositório você pode defini-los separadamente. Eu selecionei apenas a funcionalidade básica do repositório, em seu aplicativo real você pode definir a funcionalidade necessária para todos/cada repositórios.
- Data Services: Exponha todos os repositórios de entidades.
Nossas abstrações de serviços de CRM são fornecidas abaixo:
Código do Caso de uso
- Nosso caso de uso adicionar livro depende apenas das abstrações. No construtor injetamos apenas os IDataServices e ICrmServices.
- Utilizamos os nossos serviços sem saber qual é a real implementação dos mesmos.
- As alterações na implementação de serviços externos não afetariam nossa lógica de negócios de caso de uso.
Quem está injetando a implementação concreta desses serviços em nosso construtor de casos de uso? fique atento, você descobrirá em breve na seção de frameworks.
Controllers e Presenter
“O software nesta camada é um conjunto de adaptadores que convertem os dados do formato mais conveniente para os casos de uso e entidades, para o formato mais conveniente para algum órgão externo, como banco de dados ou web. É essa camada, por exemplo, que conterá totalmente a arquitetura MVC de uma GUI. Os Presenters, Views e Controllers pertencem todos aqui” — Robert C. Martin
Na seção anterior, falamos sobre nossas principais camadas de negócios e como elas dependem apenas das abstrações que definem. Agora vamos falar sobre adaptadores, então você não verá nenhuma lógica de negócios ou frameworks aqui.

Nosso controller, presenters e gateways são camadas intermediárias. Você pode pensar neles como um adaptador que cola nossos casos de uso ao mundo exterior e vice-versa.
Quem é o mundo exterior?
Se você vem do mundo MVC, provavelmente já ouviu falar sobre controllers. Em um MVC clássico você tem algum tipo de mecanismo de roteamento que aponta para os diferentes controllers. o trabalho do controller é responder à entrada do usuário, validá-la, fazer algumas coisas de lógica de negócios e, normalmente, alterar o estado do aplicativo.
O presenter, por outro lado, recebe dados de algum tipo de repositório e formata os dados para a camada view/api.
Controller
Na arquitetura limpa, o trabalho do controller é:
- Receba a entrada do usuário — algum tipo de DTO.
- Valide a higienização de entrada do usuário.
- Converta a entrada do usuário em um modelo que o caso de uso espera. Por exemplo, faça formatos de data e conversão de string para inteiro.
- Chame o caso de uso e passe o novo modelo.
O controller é um adaptador e não queremos nenhuma lógica de negócios aqui, apenas lógica de formatação de dados.
Presenter
O presenter obterá dados do repositório do aplicativo e, em seguida, criará uma resposta formatada para o cliente. Suas principais responsabilidades incluem:
- Formatar strings e datas.
- Adicione dados de apresentação, como sinalizadores.
- Prepare os dados a serem exibidos na interface do usuário.
Em nossa implementação do Node, implementaremos o controller e o presenter juntos, assim como fazemos em nossos projetos MVC. usaremos os recursos do NestJs para implementar nosso controller. validaremos nossa entrada de usuário usando pipes de validação e transformaremos nossos DTOs em objetos de negócios usando pipes de transformação.
Primeiro vamos criar nosso objeto de livro DTO. Receberemos este objeto de nossos consumidores de API.
NestsJS usa o validador de classe nos bastidores, para que possamos validar nossos objetos DTO usando decoradores de validador de classe. também podemos adicionar validadores personalizados, por exemplo, podemos adicionar um validador personalizado que verifica se o livro ainda não existe.
Este é o objeto de resposta que será retornado ao nosso consumidor:
O código do controller de livros é fornecido abaixo:
- A validação é feita por NestJs no objeto bookDto
- Estamos usando o
bookFactoryServicepara converter nosso DTO em um objeto de livro de negócios - Chama nosso serviço de casos de uso
- Crie a resposta ao consumidor
Frameworks

“Esta camada é onde todos os detalhes vão. A web é um detalhe. O banco de dados é um detalhe. Nós mantemos essas coisas do lado de fora, onde elas podem causar pouco dano” — Robert C. Martin
Na seção anterior, falamos sobre a camada de adaptadores e como eles atuam como portas de entrada e saída para nossos casos de uso.
Agora, vamos falar sobre a camada de frameworks, essa camada inclui todas as nossas implementações específicas, como banco de dados, monitoramento, cobrança, tratamento de erros, etc.
Até agora, falamos apenas sobre entidades, lógica de negócios, adaptadores, e fizemos tudo isso sem usar nenhum framework, exceto NestJs, que é nosso framework de blocos de construção. você pode dizer que escrevemos um código “puro”.
Em nosso projeto de exemplo, os frameworks são implementados como:
- A estrutura do aplicativo da Web é implementada pelo NestJs (criado no express).
- Os serviços de banco de dados são implementados usando o mangusto.
- Os serviços de CRM são um serviço simulado simples.
Implementação de serviços de dados
O código para o Repositório Genérico Mongo:
- O repositório implementa nossa classe abstrata IGenericRepository usando o mongoose.
- T representam uma entidade db, cada entidade tem toda a funcionalidade esperada.
O código do Mongo Data Services é fornecido abaixo:
MongoDataServicesimplementa a classe abstrataIDataServices.- Expõe conforme necessário 3 repositórios, um para cada entidade.
- Você pode verificar a documentação do NestJs para entender melhor a implementação do mongo, que está fora do escopo deste artigo.
Serviços de CRM:
Injeção de dependência
Como discutimos antes, nossos casos de uso dependem de contratos em vez de implementação. Esses contratos precisam ser atendidos por meio de injeção de dependência em tempo de execução.
Se você não está familiarizado com os conceitos de injeção de dependência, eu o encorajo a dar uma olhada em dois bons vídeos no blog Fun Fun Function que explicam o assunto perfeitamente:
Para nossa sorte, o NestJs possui uma funcionalidade de injeção de dependência. Tudo o que precisamos fazer é injetar nossas dependências em nosso construtor de serviço e, em tempo de execução, os NestJs cuidarão de injetar uma instância deles.
Preste atenção que injetaremos os serviços abstratos e em tempo de execução o mecanismo de DI criará uma instância da implementação correta.
Na declaração do módulo, informamos aos NestJs qual implementação queremos para cada abstração. por exemplo, quando pedimos DataServices, na verdade queremos obter uma instância do MongoDataServices.
A beleza é que nosso serviço não sabe nada sobre MongoDataServices e ainda o usa em tempo de execução.
O código para o módulo de serviços de dados é dado abaixo:
NestJs injetará a instância MongoDataServices toda vez que alguém solicitar IDataServices .
Se, por exemplo, queremos substituir o mongodb por postgresql, tudo o que precisamos fazer é:
- Crie uma nova classe de serviços de dados e repositórios que usem postgresql e siga o resumo de serviços de dados.
- No arquivo do módulo, diga ao Nest.js para usar nossos novos serviços de dados postgresql
Resumo
Neste artigo, demonstramos como construir uma estrutura robusta de serviços camada por camada que desvincula nossa lógica principal de negócios das estruturas.
Podemos substituir facilmente nosso banco de dados por Sql ou mudar para um novo sistema de CRM, tudo sem mexer em nossa lógica de negócios.
Também podemos reagir às alterações do SDK em uma de nossas estruturas tocando apenas na camada da estrutura. Os testes também são facilitados graças à arquitetura fracamente acoplada das camadas.
Em projetos complexos, é difícil e às vezes tedioso manter todas as camadas limpas e arrumadas. Trata-se sempre de compensações na arquitetura e, de vez em quando, precisamos comprometer e quebrar nossos limites para obter outro benefício.
Acredito que se nos esforçarmos para manter essas regras, obteremos grandes benefícios no futuro.
